Windows10 MYSQL Installer 安装(mysql-installer-community-5.7.19.0.msi)
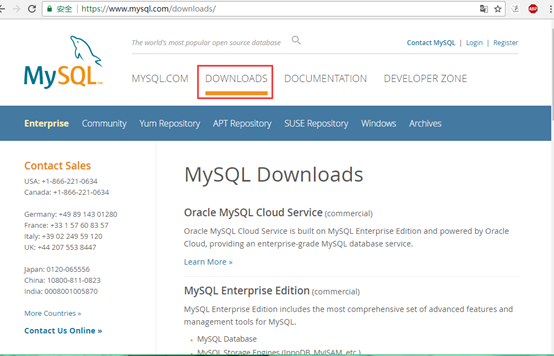
1.进入官网找到自己所需的安装包:https://dev.mysql.com/ ,路径:DOWNLOAD-->MYSQL Community Edition(GRL)-->MYSQL on Windows (Installer & Tool)
或直接点击 https://dev.mysql.com/downloads/windows/installer/ 查看最新版本。
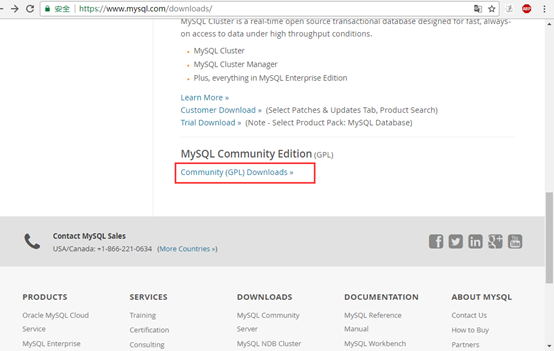
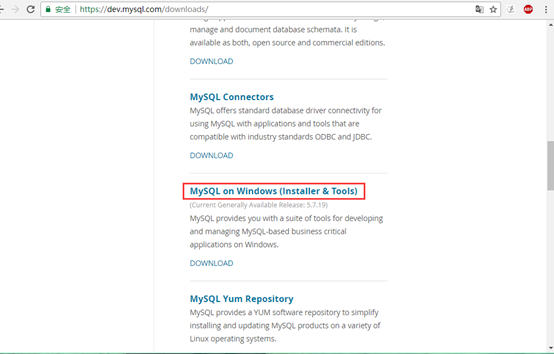
2.找到所需的安装包,
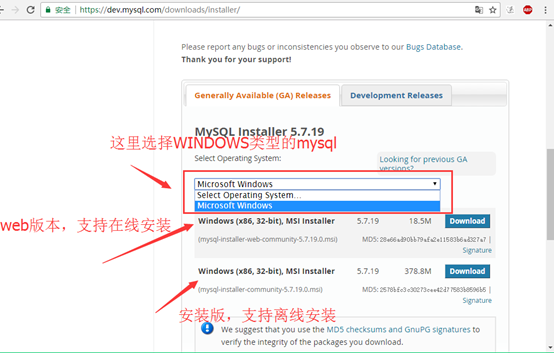
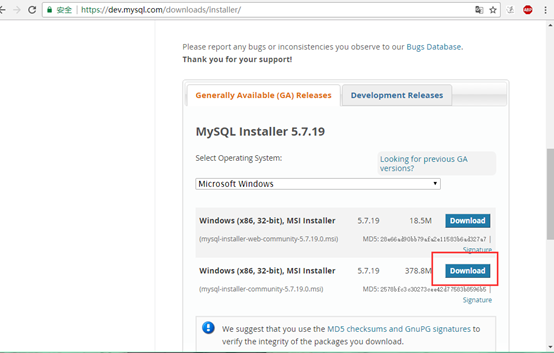
3.点击download。这里选择的是安装版(mysql -install-community)
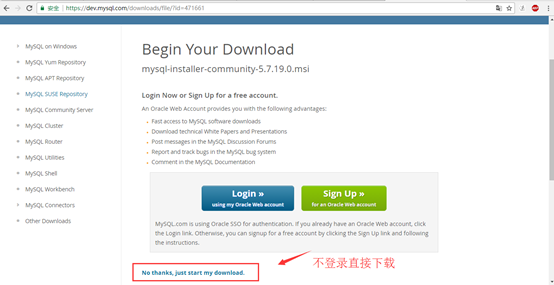
4.选择不登陆下载。
5.双击运行下载好的mysql-installer-community-5.7.19.0.msi,程序运行需要一些时间,请等待一下。
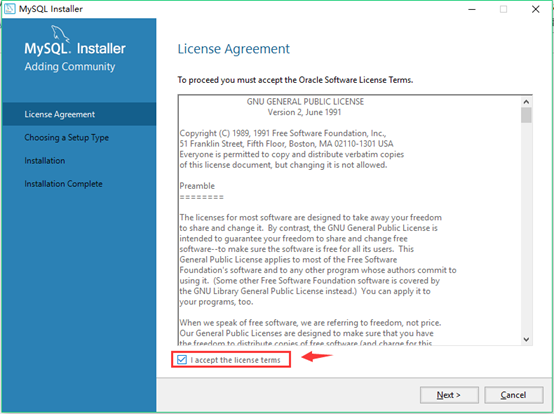
6.运行成功之后,进入欢迎的界面.选择我同意协议,不然无法进行下一步。
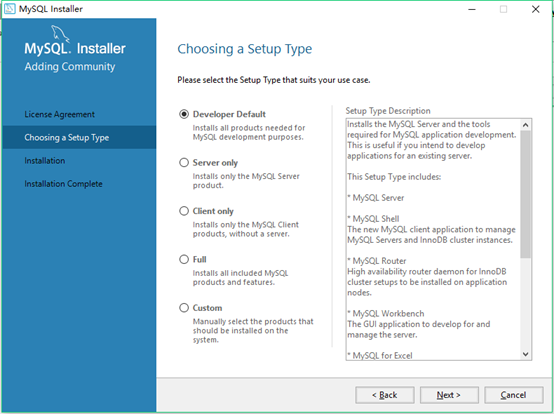
7. 进入类型选择页面,本人需要mysql云服务就选择了developer default(7.1是默认安装的步骤),如果只想安装mysql server的就选择custom模式(7.2步骤是选择自己需要的服务器类型,所选择的用于做一些数据分析)
- developer default(开发者默认):安装mysql开发所需的所有产品
- server only(服务器):只安装mysql服务器产品
- client only(客户端):只安装没有服务器的mysql客户端产品
- full(完全):安装所有包含的mysql产品和功能
- custom(手动):手动选择系统上应安装的产品
7.1开发者默认模式检测以下程序会安装不成功,点击下一步进入下一个安装流程—>跳到第八步。
check requirements:以下产品的请求失败,安装程序将自动尝试解决其中一些问题。标记为手动的要求无法自动解决。单击这些项目以尝试手动恢复。
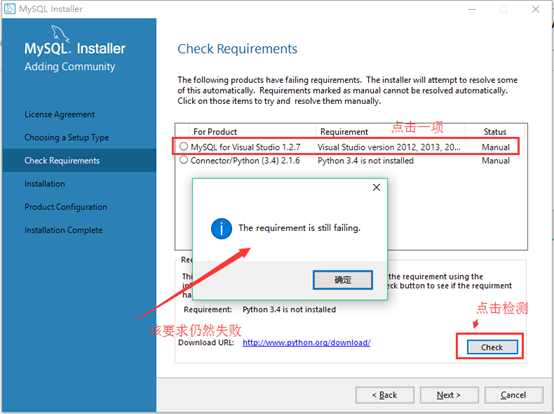
检测到不可安装的程序说明:
Visual Studio:是一款代码编辑工具(可编写C#、Visual Basic、C++、TypeScript、F# ),如果你安装的话就安装要求去安装Visual Studio version:2012.2013.2015.2017其中一个版本
Connector/pyton 3.4:电脑有python3.6了就没选择3.4版本的。如果你没安装有python可按要求去安装一些内容。
7.2选择mysql server(服务) 5.7.19 x64
选择mysql workbench(mysql 的工作薄) 6.3.9 x64
选择mysql notiyier(通知) 1.1.7 x86(因为这里只有一个选择所以选择了86)点击下一步进入下一个安装流程—>跳到第九步。
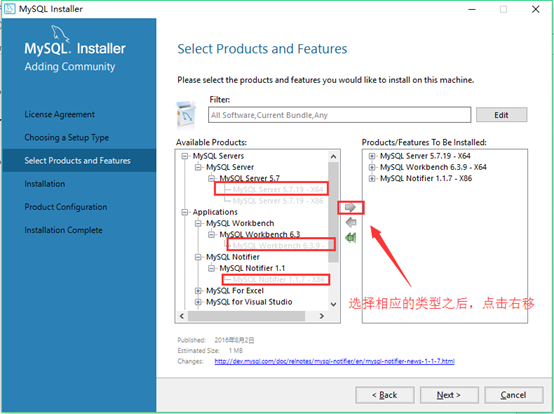
8.当我们点击下一步的时候安装程序出现了提示:(一个或者移动产品要求没有得到满足,那些符合要求的产品将不会安装/升级。你想要继续吗),这里我选择的是:YES
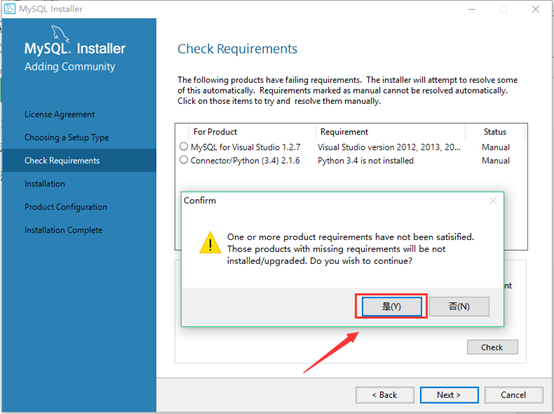
9.在安装所选界面能看到我们接下来所需要安装的程序,点击execute
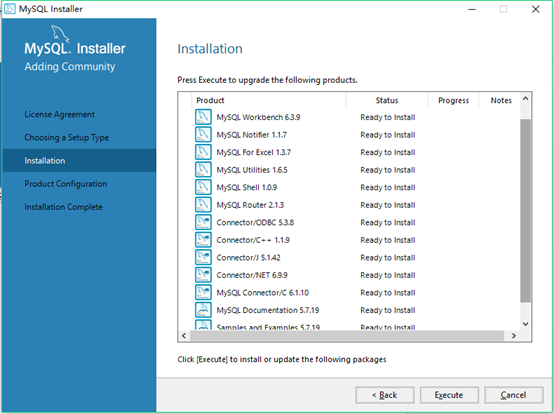
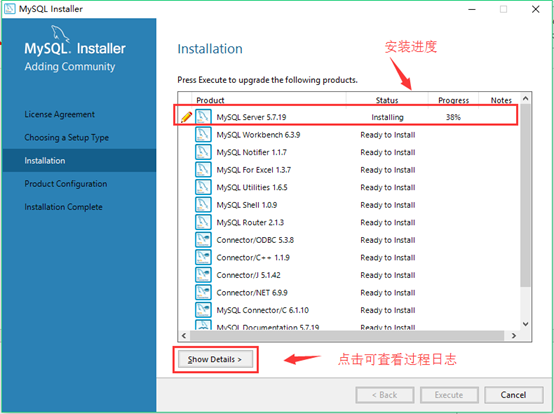
10安装程序进度界面,安装需要一些时间。点击dide tails能看到安装日志
11.程序安装完成之后,点击next
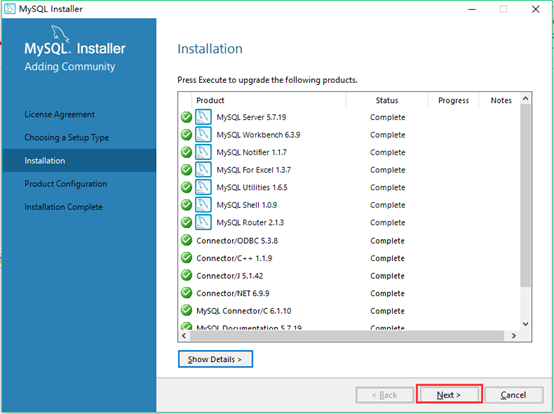
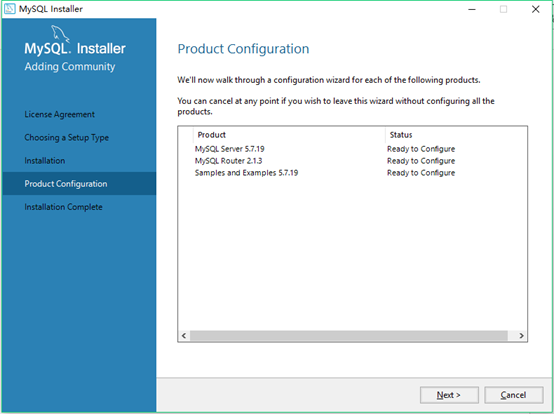
12.在product configutration(产品配置)页面能看到需要配置的程序,点击next(页面英语介绍:现在我们将逐一介绍以下产品的配置向导。您可以随时取消,如果您希望离开此向导,而不必配置所有产品)
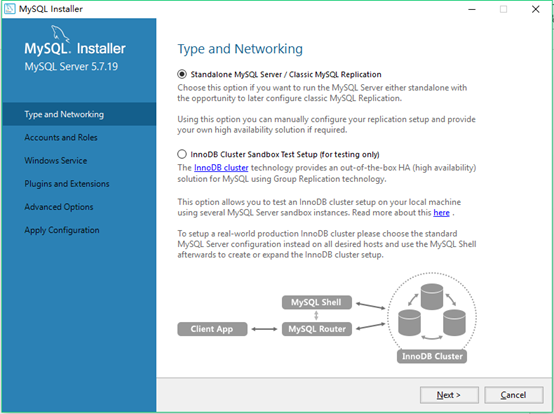
13.先配置mysql server的类型以及网络:type and networking(类型和网络),这里有两种mysql server类型,选择第一种类型点击next。
有两种类型简单介绍
- 1.standalone mysql server/classic mysql replication:独立的mysql服务器/经典的mysql复制。choose this option if you want to run the mysql server either standalone with the opportunity to later configure classic mysql replication:选择这个选项,如果你想运行mysql服务器是独立的,有机会以后配置经典的mysql复制
- 2. innodb cluster sandbox thst setup(for testing only):
innodb集群沙箱thst设置(仅用于测试)
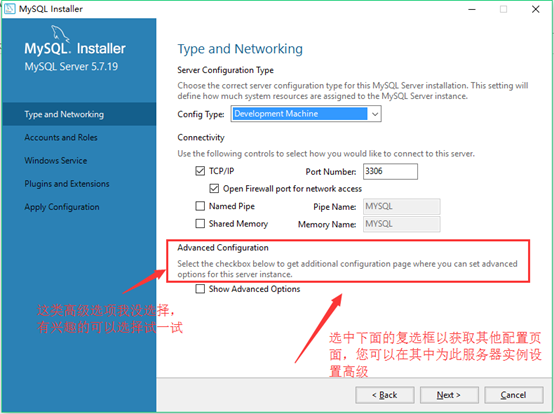
14.设置服务器配置类型以及连接端口:继续next
Config Type:选择Development Machine,用于小型以及学习所用足够了。
Port number:输入3306,也可以输入其他最好是3306-3309之间。
15.配置root的密码(该密码要记住),系统提示这密码虚弱
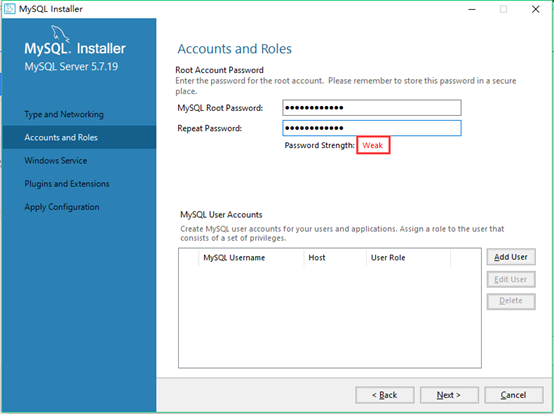
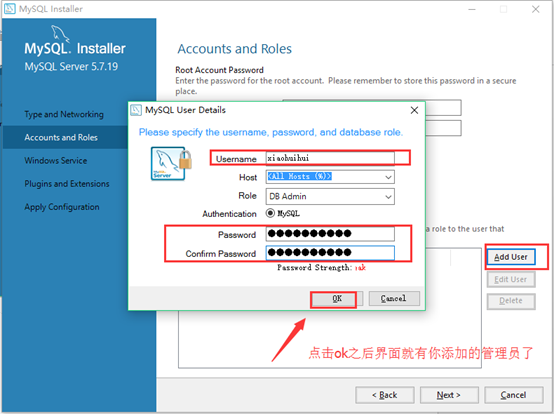
16. 添加其他管理员,点击add user 输入账号密码点击ok(如果添加的管理员只允许在本地登录就将host改成local),回到界面之后点击next
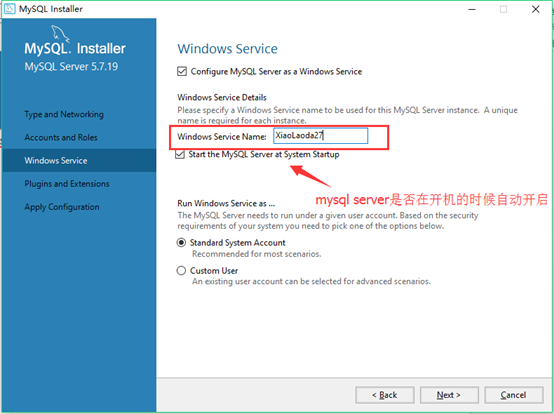
17.配置mysql在windows系统中的名字,是否选择开机启动mysql服务,其它的没进行修改,点击"Next"。
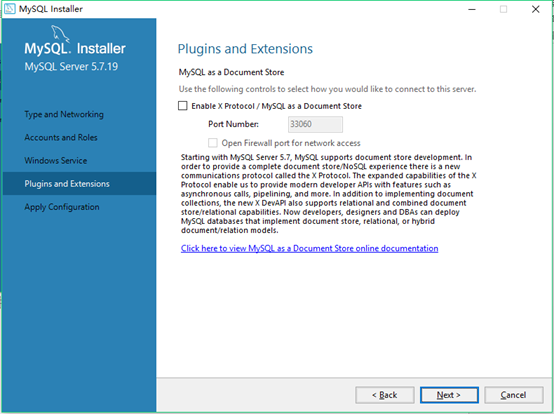
18.配置插件和扩展页面没进行修改直接下一步:
19.Mysql server :apply configuration(应用配置页面),选择execute进行安装配置
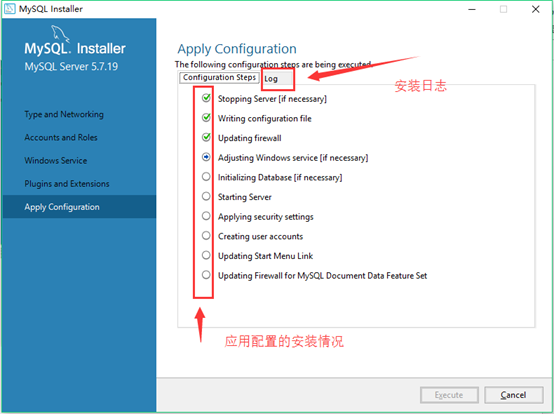
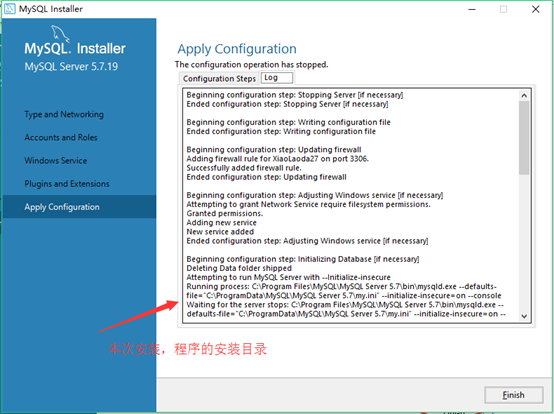
20. mysql server应用配置的log,选择finish
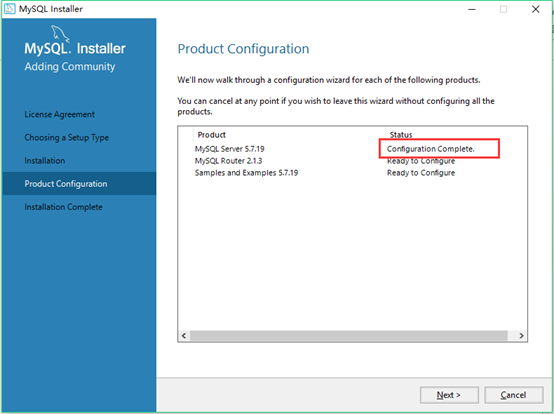
21.安装程序又回到了product configutration(产品配置)页面,此时我们看到mysql server安装成功的显示,继续下一步:
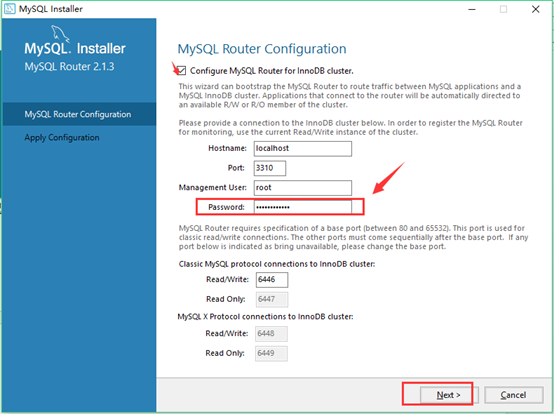
22. 配置mysql router:勾选configure mysql route for innoDB cluster之后输入密码。(如果不想输入密码可直接点击点一下)点击下一步
23.Mysql router :apply configuration(应用配置页面)点击execute,
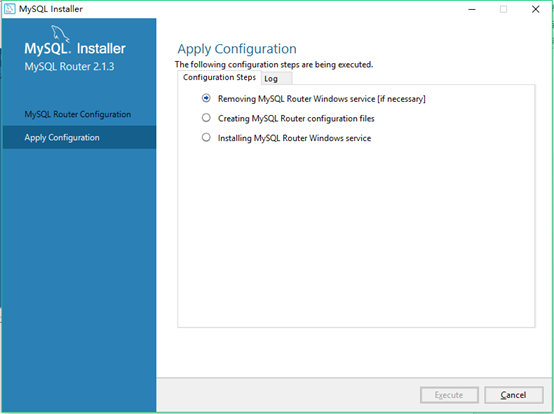
24.安装完成之后点击选择finish
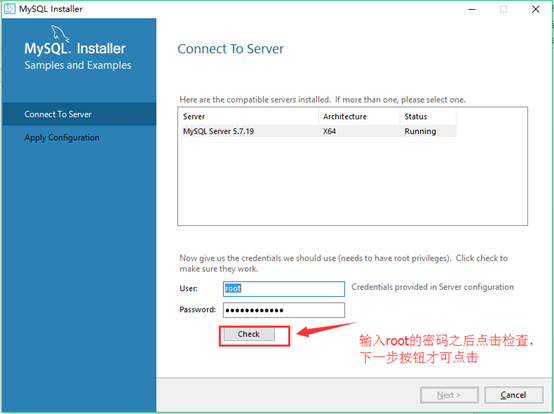
25.检测root密码
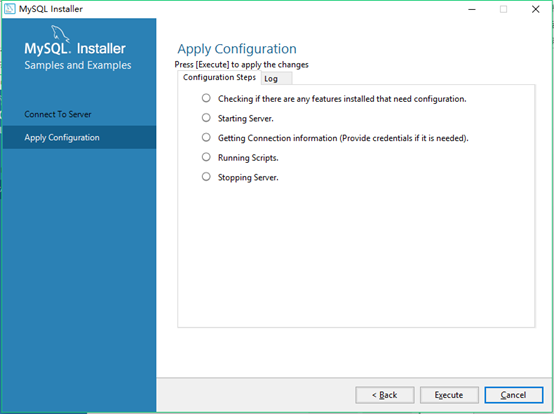
26.安装一些server,老规矩点击execute,完成之后点击finish
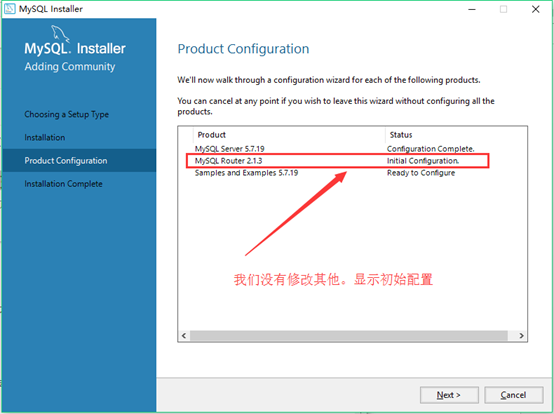
27. 程序回到产品配置页面。继续下一步:
28.安装程序完成界面。
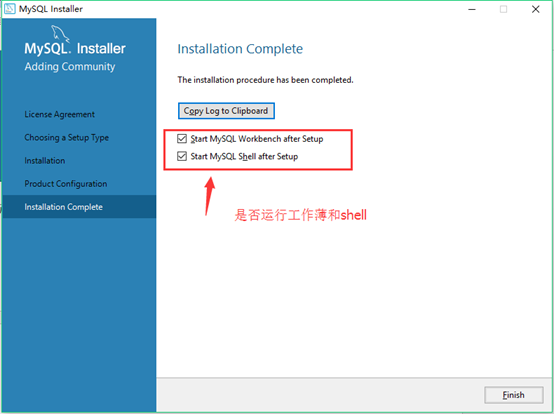
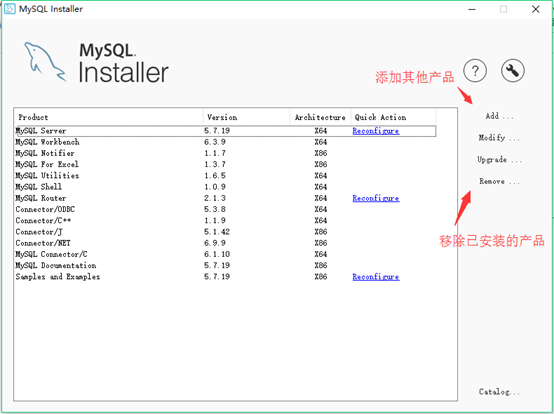
29. 双击运行之前下载的安装包,能看到我们所安装的产品。
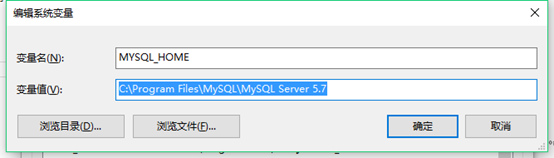
30. 配置mysql环境变量
上面安装的是时候我们看到mysql默认安装路径是:C:\Program Files\MySQL\MySQL Server 5.7
我的电脑右键—>属性à高级系统设置à环境变量à新建MYSQL_HOME,将安装目录输入:
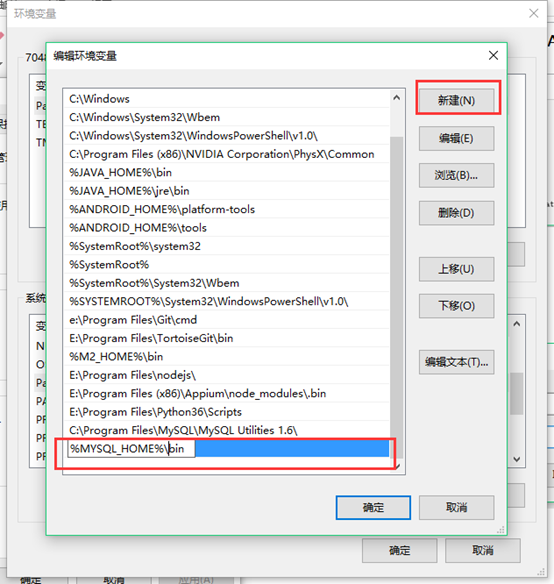
找到path编辑:输入%MYSQL_HOME%\bin
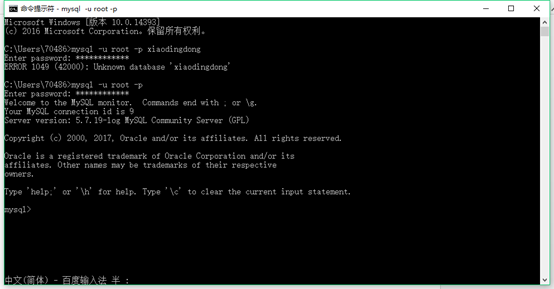
打开cmd输入mysql –u root –p
输入root的密码