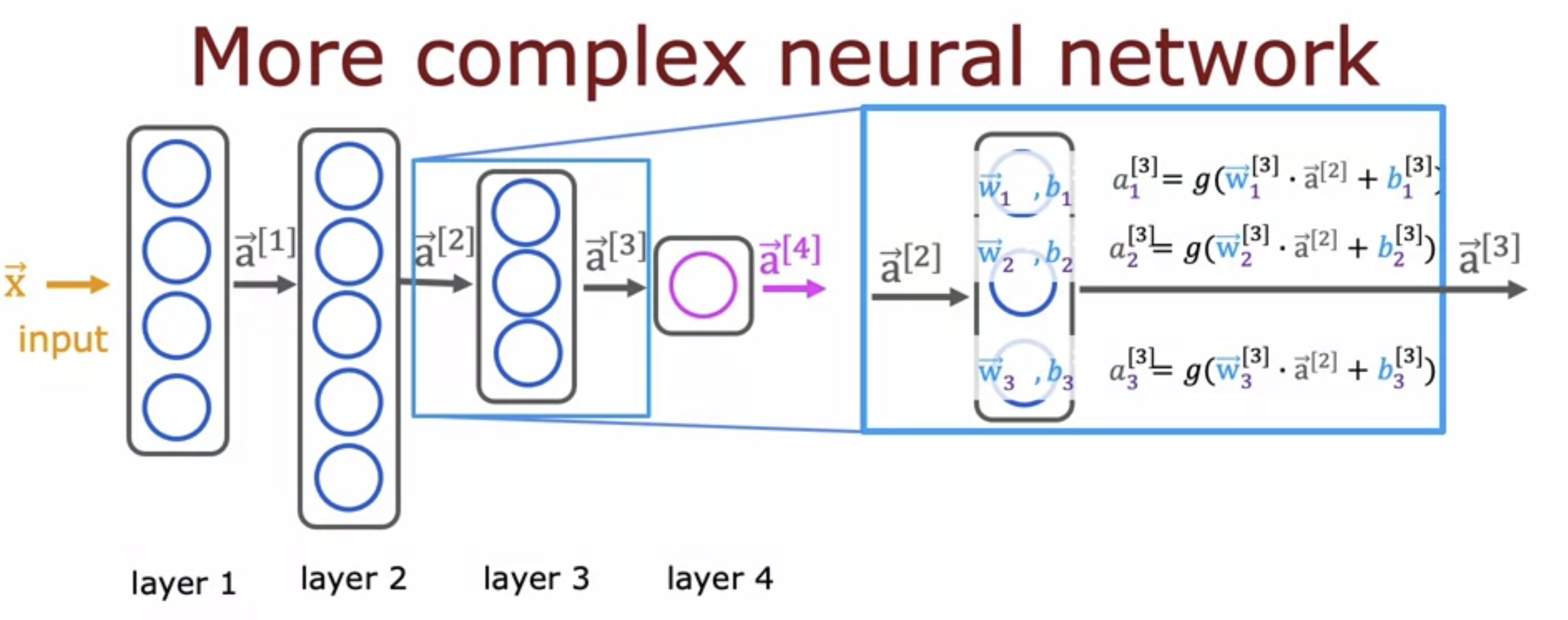
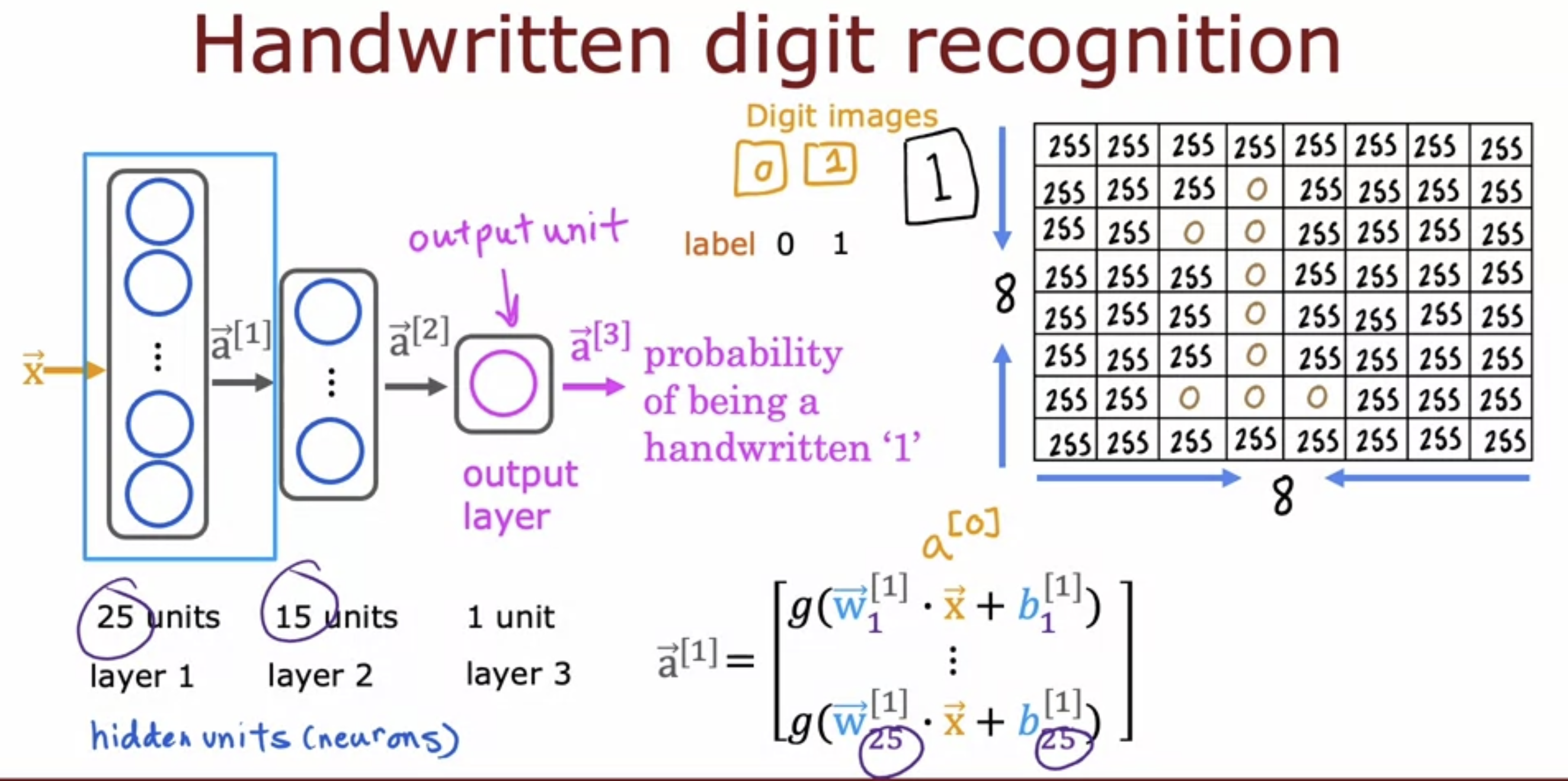
Define a
layer:layer_1 = Dense(units=3,activation='sigmoid')
Get the result from layer:a1 = layer_1(x)
Use the Sequential function to let TensorFlow build a model for you:
model = Sequential([layer_1,layer_2])
Then use model.fit(x,y) to train the model
Use model.predict(x_new) to predict
Define a model:
1 2 3 4 5 6 7 8
model = Sequential( [ tf.keras.Input(shape=(400,)), #specify input size tf.keras.layers.Dense(units=25,activation='sigmoid'), tf.keras.layers.Dense(units=15,activation='sigmoid'), tf.keras.layers.Dense(units=1,activation='sigmoid') ], name = "my_model" )
Use a loss function:
1
model.conpile(loss=BinaryCrossentropy())
After fitting make a prediction:
The input to predict is an array so the single example
is reshaped to be two dimensional.
1 2 3 4
prediction = model.predict(X[0].reshape(1,400)) # a zero print(f" predicting a zero: {prediction}") prediction = model.predict(X[500].reshape(1,400)) # a one print(f" predicting a one: {prediction}")
Originally the calculation can be done in a for loop, but by using
vector maltiplication it can be much more easier.
This image is the for loop code, it needs to get each parameter of
the neurons and multiply and plus number b.
image-2023121334422692 PM
The code for this dense function:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
defmy_dense(a_in, W, b, g): """ Computes dense layer Args: a_in (ndarray (n, )) : Data, 1 example W (ndarray (n,j)) : Weight matrix, n features per unit, j units b (ndarray (j, )) : bias vector, j units g activation function (e.g. sigmoid, relu..) Returns a_out (ndarray (j,)) : j units """ units = W.shape[1] a_out = np.zeros(units) for j inrange(units): w = W[:,j] z = np.dot(w,a_in) + b[j] a_out[j] = g(z) return(a_out)
The following img is vectorized implementation:
Code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
defmy_dense_v(A_in, W, b, g): """ Computes dense layer Args: A_in (ndarray (m,n)) : Data, m examples, n features each W (ndarray (n,j)) : Weight matrix, n features per unit, j units b (ndarray (1,j)) : bias vector, j units g activation function (e.g. sigmoid, relu..) Returns A_out (tf.Tensor or ndarray (m,j)) : m examples, j units """ Z = np.matmul(A_in,W) + b A_out = g(Z) return(A_out)
matrix multiplication
点乘是简单乘,绝大多数都是点乘.
\(\mathbf{XW}\) is a matrix-matrix
operation with dimensions \((m,j_1)(j_1,j_2)\) which results in a
matrix with dimension \((m,j_2)\). To
that, we add a vector \(\mathbf{b}\)
with dimension \((1,j_2)\). \(\mathbf{b}\) must be expanded to be a \((m,j_2)\) matrix for this element-wise
operation to make sense. This expansion is accomplished for you by NumPy
broadcasting.
Neural network training
Create the model
Define how many layers and how many units in each layer and their
activation function
Select loss and cost functions
Select a loss function such as BinaryCrossentropy() from
keras.losses
tensorflow can do it for you, you can just use
model.fit(X,y,epochs=100)
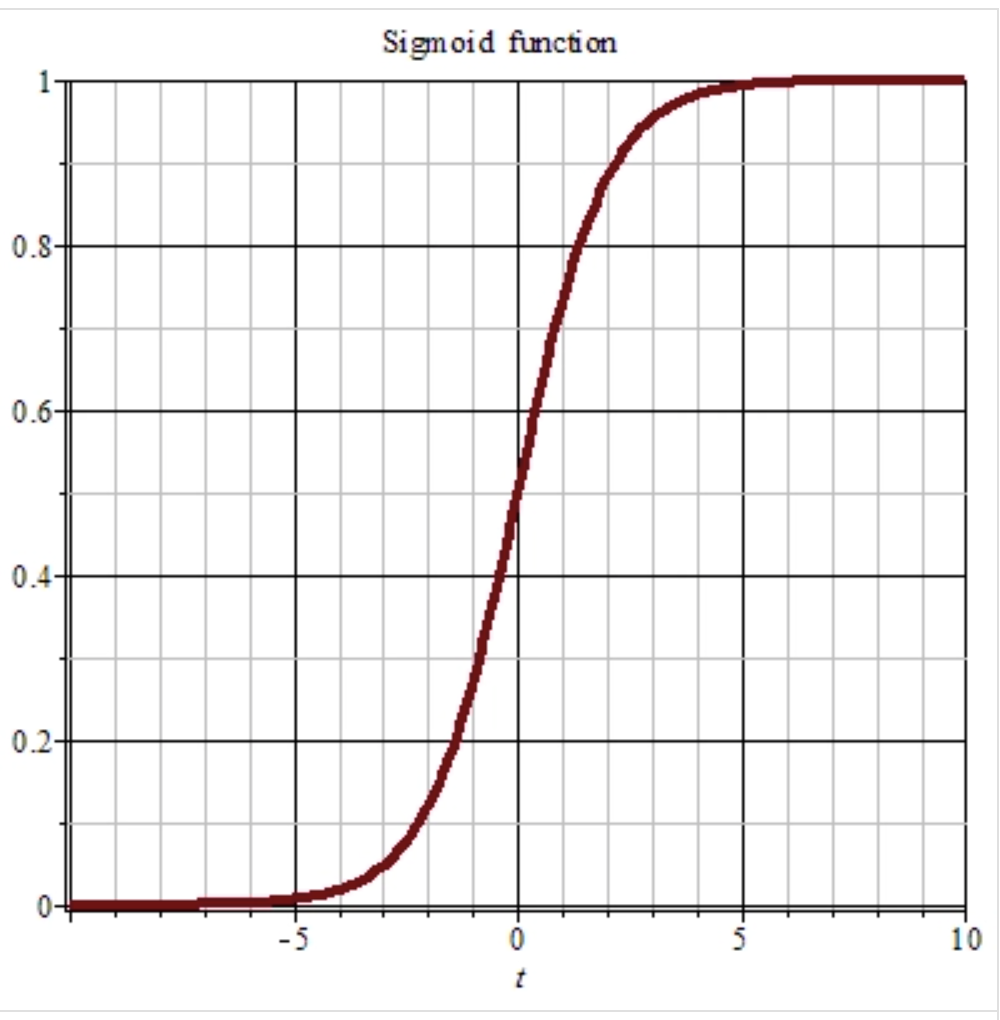
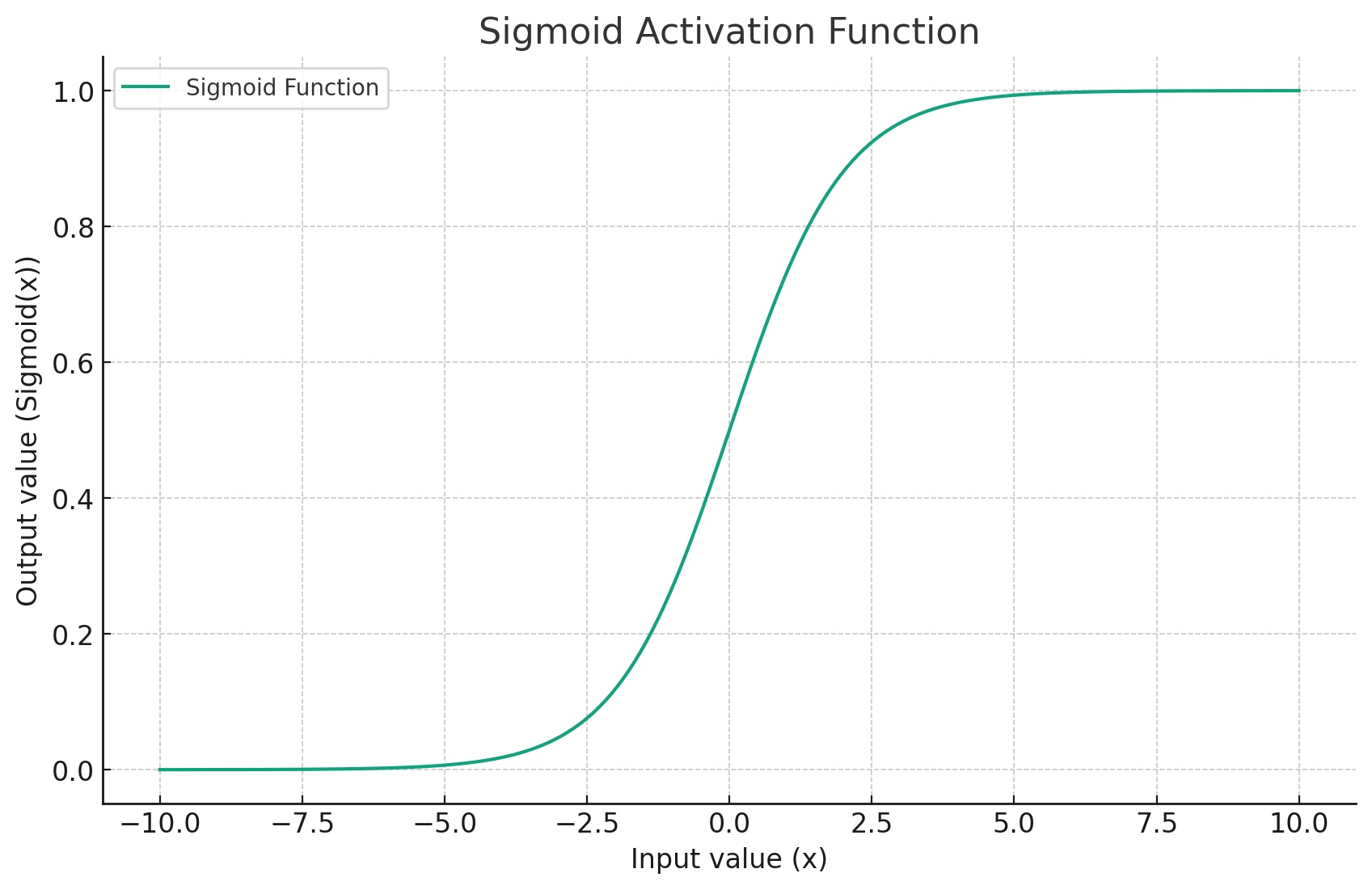
Activation Functions
Sigmoid
Better used on the binary classification problem
fbbb9b2c-c2f4-43ed-92f6-1c635dece716
The sigmoid activation function is defined as:
\[ S(x) = \frac{1}{1 + e^{-x}}
\]
where: - ( S(x) ) is the output of the sigmoid function, - ( e ) is
the base of the natural logarithm, - ( x ) is the input to the
function.
ReLU
Better used on the regression problem
The ReLU (Rectified Linear Unit) activation function is defined
as:
\[ g(z) = \max(0, z) \]
where: - ( g(z) ) is the output of the ReLU function, - ( z ) is the
input to the function.
Linear function
Better used on the regression problem
\(g(z) = z\)
What if we don't use
activation function?
It will be the same as linear regression
Multiclass Classification
Softmax algorithm
For original logistic regression using sigmoid output can be denoted
as \[ a_1 = g(z) = \frac{1}{1+e^{-z}} = P(y =
1|x) \]
Softmax allows to have multiple options being predicted with formula
as \[
a_1 = \frac{e^{z_1}}{e^{z_1} + e^{z_2} + e^{z_3} + e^{z_4}} = P(y = 1|x)
\] a是y成为某一个结果的概率
It in general can be denoted as: $$ z_j = _j + b_j j = 1, , N\
# UNQ_C3 # GRADED CELL: model import logging logging.getLogger("tensorflow").setLevel(logging.ERROR)
tf.random.set_seed(1234) model = Sequential( [ ### START CODE HERE ### tf.keras.layers.Dense(units=120,activation='relu'), tf.keras.layers.Dense(units=40,activation='relu'), tf.keras.layers.Dense(units=6,activation='linear') ### END CODE HERE ###
], name="Complex" ) model.compile( ### START CODE HERE ### loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), optimizer=tf.keras.optimizers.Adam(learning_rate=0.01) ### END CODE HERE ### )
Reconstruct your complex model, but this time include regularization.
Below, compose a three-layer model:
Dense layer with 120 units, relu activation,
kernel_regularizer=tf.keras.regularizers.l2(0.1)
Dense layer with 40 units, relu activation,
kernel_regularizer=tf.keras.regularizers.l2(0.1)
Dense layer with 6 units and a linear activation. Compile using
loss with SparseCategoricalCrossentropy, remember to
use from_logits=True